Considering the originality of the text we are dealing with, we decided to use several automated tools along with our analogical interpretation of the text. Our aims where, on the one hand, achieving a comprehensive understanding of the content of the text on a conceptual level, on the other hand annotate the text syntactically and semantically to be able to inquire deeper in the relation between Haraway's theory and the semiotics that convey it.
[TOPIC MODELLING]
Along with the personal interpretation of our sources , we used BERTopic to extract meaningful topics, especially the central theoretical concepts, from the text.
Find here the documentation of this step as well as the visualization of the book's extracted topics.
[Named Entity Recognition, POS tagging, dependency and more]
We used BookNLP natural language processing pipeline that scales to books and other long documents (in English). To fully annotate the text and extract its main entities as well as their relations and dependencies.
The pipeline produces 6 files: Tokens, Entities, Supersense, Quotes (csv) and two Book files (json and html).
Althought the entire output was useful for in-depth analysis of Staying with the trouble it didn't seem to perform very accurately on it, according to our needs, probably because of the philosophical and poetic content, in comparison to more narrative texts.
For this reason we decided to concentrate only on one chapter, Chapter 7: A Curious Practice and manually correct the output of the tokens file. This process allowed us to precisely access the tool's accuracy and to obtain useful data for the creation of our ontology vocabulary and model. Click here to read the documentation about the workflow
[FRED and FrameNet]
FRED is a machine reader for the Semantic Web: it is able to parse natural language text in 48 different languages and transform it to linked data.
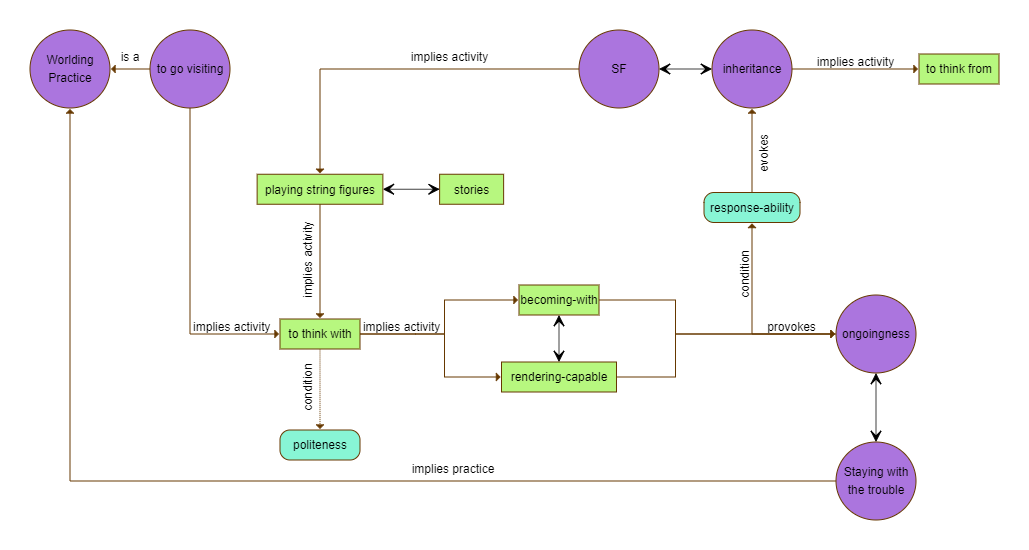
Our initial aim was to exploit FRED's output to add semantic role labeling of the entities we extracted in the previous steps. Unfortunately, this task resulted too time-consuming and complex to preform in the contest of this project, that's why we decided to try and mimic fred's semantic notation through a more simple, semi-automated process that implied manually annotating identified Frames and Roles in the first paragraph of Chapter 7 and creating a Python pipeline to automatically create instances of entities and their relation, according to our designed Ontology model.
To annotate Frames we studied FrameNet project and went through its lexical units index to see if we could classify our sentences in appropriate FrameNet frames. When suitable, we adopted FrameNet data, otherwise we created our own Frame, such as in the case of the Frame Collaborative_thinking, give that it evokes a semantic concept that is original to Donna Haraway's theory.
The identification of frames in the text was carried out following this workflow:
Identification of all the main concepts
Individuation of the significant terms related to each concept and relation of concepts between them
Abstraction into Frames evoked by the previous conceptualization
Aligning identified Frames with FrameNet's where possible
Listing of lexical units (concept-related identified lexical units + new FrameNet related lexical unit)
Find here all annotated Frames of our first paragraph.
[KNOWLEDGE GRAPH AND ONTOLOGY EVAUTATION]
[KNOWLEDGE GRAPH]
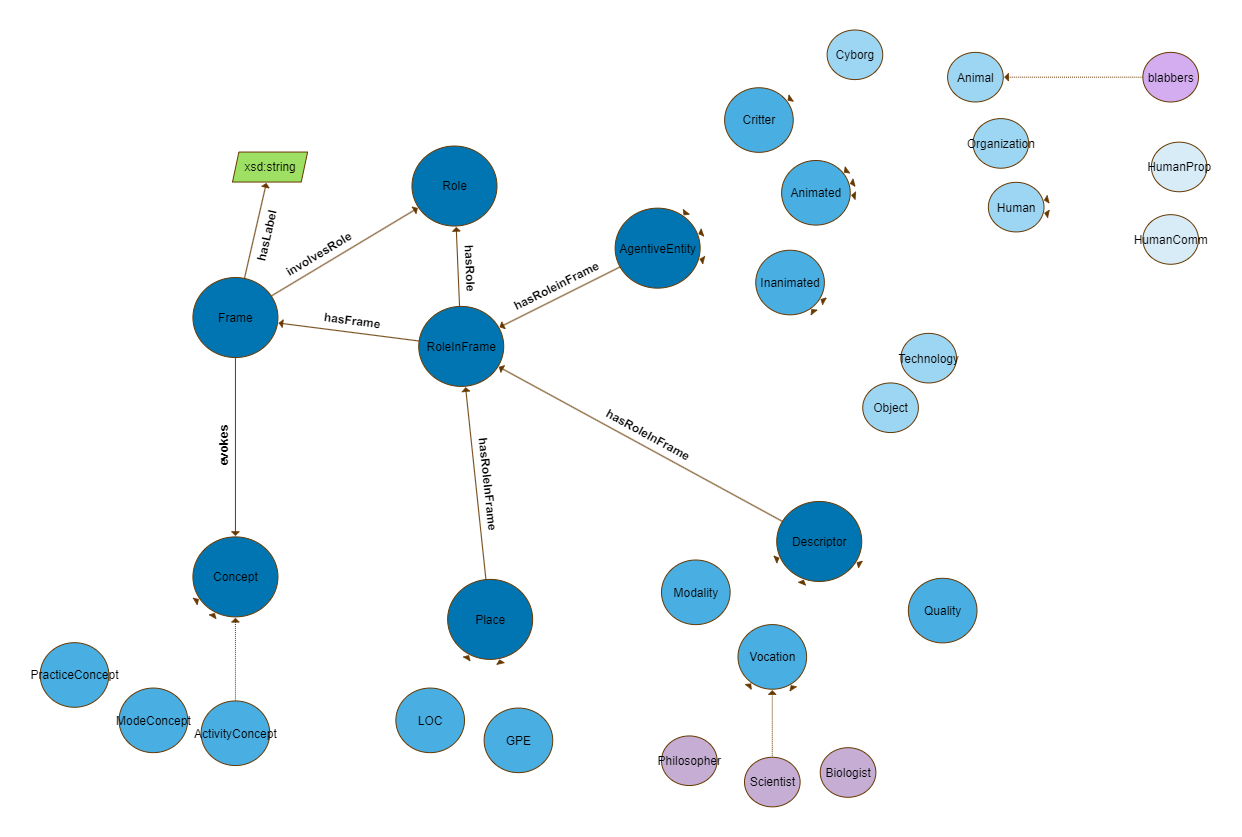
Since the ontology as designed is meant to be populated automatically by means of text parsing, we designed our own algorithm to perform such task.
The python code takes in input two datasets:
- "alignment.csv": a dataset manually written to align BookNLP output (ex. POS tagging) with our ontology Classes and indentified Frames and Roles
- BookNLP .tokens file, to parse each sentence and be able to reach related synctactic and morphological information.
In addition, the two RDF of our ontologies (ChthuluConcepts.ttl and ChthuluOnt.ttl) exported from protégé are parsed and needed triples for class hierarchies and mapping are added to the main ChthuluGraph.
The libraries pandas and rdflib are used to manipulate the data and build the Knowledge
Here is the algorithm desing
![]() Download the python file
Download the python file
Here is the visualization of the final KG:
[Named Entity Recognition, POS tagging, dependency and more]
We used BookNLP natural language processing pipeline that scales to books and other long documents (in English). To fully annotate the text and extract its main entities as well as their relations and dependencies.
The pipeline produces 6 files: Tokens, Entities, Supersense, Quotes (csv) and two Book files (json and html).
Althought the entire output was useful for in-depth analysis of Staying with the trouble it didn't seem to perform very accurately on it, according to our needs, probably because of the philosophical and poetic content, in comparison to more narrative texts.
For this reason we decided to concentrate only on one chapter, Chapter 7: A Curious Practice and manually correct the output of the tokens file. This process allowed us to precisely access the tool's accuracy and to obtain useful data for the creation of our ontology vocabulary and model. Click here to read the documentation about the workflow
[FRED and FrameNet]
FRED is a machine reader for the Semantic Web: it is able to parse natural language text in 48 different languages and transform it to linked data.
Our initial aim was to exploit FRED's output to add semantic role labeling of the entities we extracted in the previous steps. Unfortunately, this task resulted too time-consuming and complex to preform in the contest of this project, that's why we decided to try and mimic fred's semantic notation through a more simple, semi-automated process that implied manually annotating identified Frames and Roles in the first paragraph of Chapter 7 and creating a Python pipeline to automatically create instances of entities and their relation, according to our designed Ontology model.
To annotate Frames we studied FrameNet project and went through its lexical units index to see if we could classify our sentences in appropriate FrameNet frames. When suitable, we adopted FrameNet data, otherwise we created our own Frame, such as in the case of the Frame Collaborative_thinking, give that it evokes a semantic concept that is original to Donna Haraway's theory.
The identification of frames in the text was carried out following this workflow:
Identification of all the main concepts
Individuation of the significant terms related to each concept and relation of concepts between them
Abstraction into Frames evoked by the previous conceptualization
Aligning identified Frames with FrameNet's where possible
Listing of lexical units (concept-related identified lexical units + new FrameNet related lexical unit)
Find here all annotated Frames of our first paragraph.
To build our #chthuluontology, we identified concepts and frames, according to the unique storytelling of Donna Haraway.
framesLU =
{"Collaborative_thinking" : ["thinks-with", "attunement"],
"Perception_active" : ["listened"],
"Coming_to_believe" : ["learned"],
"Studying" : ["studies"],
"Coming_up_with" : ["theorizes", "theory", "proposes"],
"Mental_stimulus_stimulus_focus" : ["interested in"],
"Cause_expansion" : ["enlarges", "dilates", "expands", "adds"],
"Being_in_category" : ["practice"],
"People_by_vocation" : ["who", "scientist"],
"Needing" : ["needy"]}
conceptsLU =
{"ThinkWith": ["thinks-with", "kind of thinking", "built together"],
"GoVisit": ["going visiting"], "RenderCapable" :["render each other capable"],
"Worlding" : ["worlding"],
"Ongoingness" : ["yet to come"]}
BookNLP delivers a set of outputs. Below you can find the .entities file; as you will notice, some entities are not correct. Furthermore, the recall for the entire book becomes incrementally accurated when it comes to terms such as "situated", a very important expression in Haraway's whole production.